AWS | Cloud
Three Calls To Action for Security On AWS 
Steyn Huizinga 01 Aug, 2022





In one of my previous blog posts we discussed a number of data and security-related topics. One of the topics that were discussed was about handling personal identifiable information (PII) data and complying with regulations like GDPR. In this blog post, I want to dive a bit deeper into that topic and give a few examples of services that can be used for handling Personal Identifiable Information in your data with AWS.
Data is often considered to be the new oil or gold, depending on whether you prefer sticky or shiny things. Because of that, applications tend to collect as much data as they can in order to get the maximum value of it. Collecting and storing all that data will likely result in storing some personal identifiable information.
The definition of what is considered PII data differs between regulators, e.g. specific data points like a credit card number or name versus collecting enough contextual data to be able to point to a specific person. In this blog post, the focus will be on how to deal with specific data points, although it can be a basis for dealing with contextual data as well.
However, it might not always be evident if your data contains specific information about people. You might for instance allow users to upload documents. Those documents could possibly contain sensitive data without you actually knowing it. Luckily AWS has a few services that can help with detecting these types of data.
Amazon Comprehend is a service that uses natural language processing to analyze texts and return all kinds of insights about them like sentiment, topics, and entities. However, Amazon Comprehend also detects PII in your text. As it currently stands Comprehend only supports PII-detection in English. If you are using any of the other supported languages by Comprehend you could try and train your own custom classifier to sidestep the missing functionality.
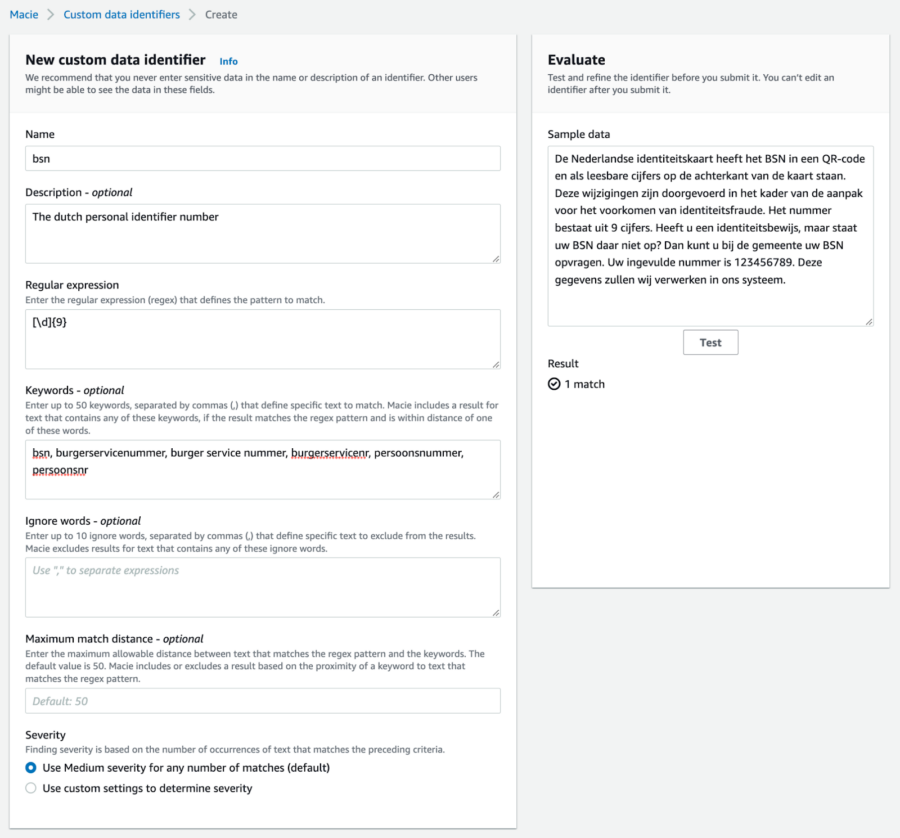
Amazon Macie is described by AWS as a fully managed data security and data privacy service. It has a couple of features that help you improve your security and privacy. One of them is detecting sensitive and PII data in your objects stored in S3 buckets on AWS. It can scan documents like pdf and docx to detect any number of data types that can be considered sensitive or personal. The number of data types that it can detect is quite extensive but might not cover all your use cases. One of the nice things about Amazon Macie is that you can register custom data identifiers. Adding an identifier for a dutch personal identification number could be done by specifying the regular expression and optionally some keywords to improve accuracy.
The third option that I want to share with you is using AWS Glue to detect PII in your data pipelines. Although AWS Glue is probably used mostly for its ETL capabilities, it can also do some neat little tricks. One of them is detecting PII in the data that goes through your AWS data pipelines. Just as with Comprehend and Macie it mostly focuses on US data types like US passport numbers or social security numbers along with some generic types like names, email addresses, and IP addresses. However, as with Macie you can extend the detection capabilities of AWS Glue by creating your own custom identifier.
Now that we know where we actually store the personal information we can act on it. Depending on your use case you might start with redacting those parts of the data or by simply deleting it. In the next section, I want to walk you through the steps of redacting PII in your AWS Glue data pipelines.

