Agile Architecture
Performance on Amazon AWS 
Michiel Sens 14 Oct, 2012





Amazon Simple Storage Service (S3) is one of the core storage services from AWS. S3 Buckets are used by millions of AWS customers, and in this article, we dive into how the performance of S3 can be optimized.
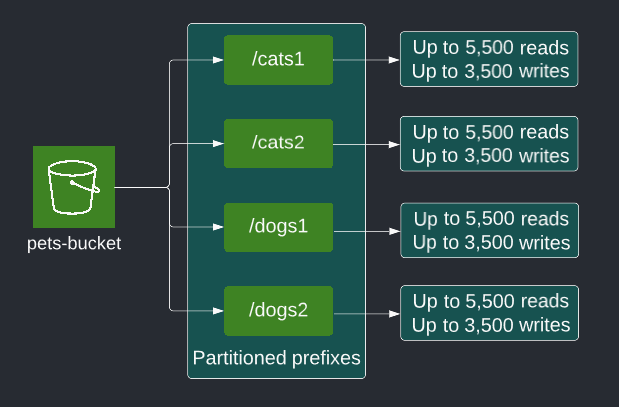
Using prefixes enables scaling for high request rates. S3 supports up to 3,500 writes and 5,500 reads per second per partitioned prefix. Each partition is a logical entity that S3 uses internally to index the object keys. Object keys initially reside in a single partition.

Requests exceeding the allowed capacity results in a HTTP 503 slowdown error. As S3 detects sustained request rates that exceed a single partition’s capacity, it creates a new partition per prefix in your bucket. As the throughput requirement grows for your workloads, the partitioned prefixes scale accordingly without any upper limits on how many partitioned prefixes are used.
S3 is a large-scale distributed system. To take advantage of its scale, read and write requests to S3 can be parallelized on large objects instead of a single request. This approach helps distribute requests over multiple paths through the network. S3 has no limitations on the number of connections made to a S3 bucket.

For single large objects the Range HTTP header can be used to download the object in parts, transferring only the specified portion. By using parallel concurrent connections to S3 to read different byte ranges from the same object, it enables higher aggregate throughput versus a single whole-object read.
Similarly a single large file can be written to S3 by uploading it in parts in parallel by using multipart upload. Each part furthermore has the flexibility of being paused/resumed and retried on errors. The multipart upload is a 3-step process:
In highly distributed systems such as S3, a small percentage of connection delays and failures is to be expected. S3 has mechanisms to detect resource overconsumption and reply accordingly. HTTP 503 slowdown and HTTP 500 can be expected during high request rates. To build resilient architectures these 2 techniques can be applied:
How these 2 techniques are best implemented depends on your S3 workload. Parameters to assess when identifying the optimal timeout and retry count & delay are:
S3 Select is a feature that allows you to retrieve specific data from the contents of an object using SQL expressions. By reducing the amount of data that S3 transfers, you minimize transfer costs and improve performance.
S3 Select works on objects stored in CSV, JSON and Apache Parquet format. It also works on CSV & JSON objects compressed with GZip and BZip2. The SQL result set can either be in CSV or JSON, nested data only in JSON.
The below example describes a dataset of relational data, on which SQL query will return the first and last name of the person who has the identifier of ‘9346’. This example demonstrates the concept of how a large dataset can be queries within milliseconds in the application via SDKs or via the AWS Console ad hoc.

CloudFront is a global content delivery network (CDN) that delivers content to the viewers with low latency and high transfer speeds. CloudFront uses edge locations to cache copies of your S3 content in a location closest to the viewer. The cached content request and response travels a shorter distance than to your S3 region, and thus delivers an improved performance. Non-cached content is retrieved by CloudFront from S3 and cached as needed.
CloudFront uses several optimizations to deliver a high performance, such as TLS session resumption, TCP fast open, OCSP stapling, S2N, and request collapsing. HTTP/1.0, HTTP/1.1, HTTP/2 and HTTP/3 are supported.
Furthermore, direct access to S3 can be restricted, only allowing access to the content from CloudFront. This can be enabled by using origin access identity (OAI). HTTPS encryption can also be enforced if encryption-in-transit between CloudFront and the viewer is required.
Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between the client and S3 bucket. Transfer Acceleration takes advantage of CloudFront’s global network of edge locations, by routing data closest to the edge, so it travels a shorter distance on the public internet and in majority on the AWS backbone of optimized network.
Transfer Acceleration uses standard TCP and HTTP/HTTPS ports, so it does not require any custom firewall configuration. Transfer Acceleration is ideal for transferring gigabytes to terabytes of data across continents or for uploading to a centralized bucket from across the world.
If your objects are in megabytes, consider using CloudFront instead of Transfer Acceleration.
Each time Transfer Acceleration is used to upload data, it checks internally if it can provide acceleration compared to traditional S3 transfer. If there are no benefits, the data is transferred through standard S3 transfer and no extra charges occur.
AWS provides a Transfer Acceleration speed comparison tool, so a comparison can be made between accelerated and non-accelerated S3 transfer. This tool uses multipart upload to transfer a file from the browser to various S3 Regions with and without acceleration.
To test transfer speed with your bucket and region, modify the URL as following:
A key part of achieving optimal S3 performance is to get the necessary insight into S3 performance. CloudWatch is a monitoring and observability service that monitors applications and services and provides a unified view of operational health.
CloudWatch uses metrics and dimensions to provide the necessary visualization of the operational health. Metrics represent a time-ordered set of data points, such as number of requests made to a S3 bucket. Dimensions represent a key-value pair of the identity of the metric, such as ApplicationEnvironment=Test. Dimensions can be used for filtering of the metrics.
Metrics and dimensions are visualized in the form of charts and diagrams in a dashboard or used for alarms to notify personnel or automate an alarm response process.
Key metrics provided by S3 are grouped into:
Interested in learning more about working scalable and security on S3? Check out this blog by my colleague Steyn!


